1. 개요
LIS는 Longest Increasing Sequence의 약자로 특정 값들이 저장되어 있는 배열 형태에서 순차적으로 증가하는 부분 수열 중 가장 길이가 긴 것을 의미한다.
예를 들어, 현재 아래와 같은 배열이 있다고 가정하자.
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
여기서 가장 긴 증가하는 부분 수열, 즉 LIS는 어떤 것이 있을까? 우선 각 숫자가 이전의 수보다 크다면, 그 순서가 가장 큰 경우를 구해보자. 그 배열을 sequence의 약자인 seq라고 해보자.
우선 i = 0 인 arr[0] = 10 일 때, 자기 자신 혼자 있더라도 수열을 만들 수 있으며 혼자서라도 LIS의 일부가 될 수 있으니 1로 시작할 수 있다.
arr[1] = 20, 20은 이전의 10보다 크니까 seq는 2이다.
arr[2] = 40, 40은 이전의 20보다 크니까 seq는 3이다.
arr[3] = 30, 30은 이전의 40보다는 작지만 그 이전의 20보다는 크다. 따라서 seq는 3이다.
arr[4] = 1, 1은 이전의 모든 숫자보다 작다. 따라서 seq는 1이다.
arr[5] = 3, 3은 이전의 1보다 크지만 그 이전의 숫자보다는 작다. 따라서 seq는 2이다.
arr[6] = 5, 5는 이전의 1, 3보다 크지만 그 이전의 숫자보다는 작다. seq는 3이다.
arr[7] = 2, 2는 이전의 3, 5보다 작고 1보다 크지만 그 이전보다는 작다. seq는 2이다.
arr[8] = 90, 90은 이전의 모든 숫자보다 크다. 따라서 이전의 숫자 중 seq가 가장 높은 숫자에 1을 더해야 한다. seq=3이 가장 큰데, 이에 해당하는 것은 arr[2]=40, arr[3]=30, arr[6]=5 인 경우이다. seq는 4이다.
이제 아래의 배열을 살펴보자.
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| seq[i] | 1 | 2 | 3 | 3 | 1 | 2 | 3 | 2 | 4 |
이 예제를 통해, 우리는 LIS는 부분적으로 여러 개가 존재할 수 있다는 것을 알 수 있다. 하지만 최대 길이 그 자체는 하나의 숫자로 정해진다.
2. 알고리즘 풀이
LIS를 어떻게 효율적으로 구할 수 있을까? 보통 3가지 정도로 정리할 수 있다.
① 완전탐색
단순하게 생각하면 그 배열 내에서 각 위치의 데이터를 기준으로 하나 하나 다 비교하며 길이가 얼마나 되는지 확인하면 된다.
즉, 배열 내 모든 증가 수열을 모두 파악하여 그 길이를 비교하는 방법으로 수행하는 것인데, 이 방법을 완전탐색 방식이라고 한다.
이 방식은 간단하게 코드로 옮기면 다음과 같다.
package com.test;
public class LIS{
public static void main(String[] args){
int[] arr = new int[]{10, 20, 40, 30, 1, 3, 5, 2, 90};
int result = 1; // 일단 최소한 1이 답이 될 수 있다.
int[] lis = new int[arr.length]; // LIS 길이 값을 저장하는 배열
int max_lis = 1; // LIS의 길이 중 가장 긴 값을 저장
for(int i=0; i < arr.length; i++){
result = Math.max(result, exhSearch(arr, i)); // 각 부분에서 시작해 완전 탐색
lis[i] = result; // 결과값 저장
max_lis = Math.max(max_lis, result); // 현재 까지의 최장 길이 저장
result = 1; // 다시 result는 1로 초기화(각 index의 실제 LIS를 알기 위함)
}
System.out.println("LIS 길이 : " + max_lis);
// *********** 여기까지가 LIS 길이 구하는 부분. ***************
// 아래 부분은 추가로 참조
// LIS 길이 값 출력하기
System.out.println("각 index의 LIS 값");
for(int i=0; i < lis.length; i++){
System.out.print(lis[i] + ", ");
}
System.out.println();
// LIS에 따른 배열 출력해보기
System.out.println("LIS 배열 출력하기");
int start = 1; // max_lis 까지 순환
for(int i=0; i < arr.length; i++){
for(int j=start; j <= max_lis; j++){
if(lis[i] == j){
System.out.print(arr[i] + ", ");
start++;
break;
}
}
}
}
public static int exhSearch(int[] arr, int idx){
if(idx == 0) return 1; // 맨 처음 1개일 때는 자기 자신만으로 LIS 구성. 1반환
int ret = 1; // 1에서부터 시작
for(int i=idx-1; i >= 0; i--){
// 만약 현재 위치보다 이전의 값들이 자기 자신보다 작다면 LIS의 대상이 될 수 있으니
// 해당 위치를 기준으로 재귀를 통해 지속 탐색 수행
if(arr[i] < arr[idx]){
ret = Math.max(ret, 1+exhSearch(arr, i));
}
}
return ret;
}
}
/*
결과
LIS 길이 : 4
각 index의 LIS 값
1, 2, 3, 3, 1, 2, 3, 2, 4,
LIS 배열 출력하기
10, 20, 40, 90,
*/
이 방식은 각 Index에서 시작하여 제일 증가하는 부분 수열을 찾아 반복 + 재귀문을 사용하여 푸는 방식이다.
각 index에서 시작하여 재귀를 통해 또 호출하고 있어서 복잡한데 전체 시간복잡도가 O(2^N)이 된다.
완전 탐색 알고리즘은 추후 별도 포스팅으로 다룰 예정.
② DP(Dynamic Programming)
사실 이 문제는 DP를 통해 더 효율적으로 해결할 수 있다. DP 관련 포스팅은 여기를 참조.
위 코드에서 index 0~4의 5개의 원소가 들어간 경우라고 가정하였을 때, index4에서 부터의 호출 방식은 아래와 같다.
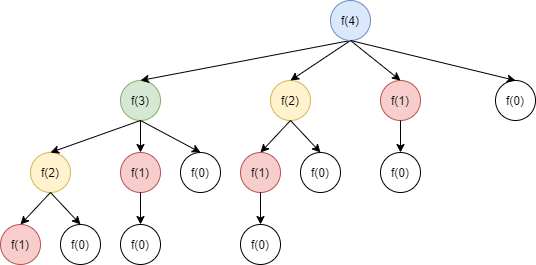
위와 같은 방식이 0~4까지 반복되므로 시간복잡도가 O(2^N)으로 측정된다. 그런데, 해당 트리를 잘 보면 동일한 작은 문제가 반복되고 있으며 그 아래의 작은 문제가 최적결과가 있다면 그대로 사용할 수 있음을 알 수 있다.
따라서, DP의 2가지 조건인 Overlapping Subproblems와 Optimal Structure가 모두 충족되어 DP를 통해 해결할 수 있다.
DP로 해결한다면 위의 문제에서 문제의 정의가 어떻게 되는지 생각해보자. 아래와 같을 것이다.
정의 : 길이 N의 배열에서 LIS의 길이를 구하기.
다 아는 내용인데 왜 저런 문장화를 굳이 했을까? DP의 포스팅에서도 언급하였지만 DP를 해결하기 위해서는 State, 즉 변수가 될 상태 값에 대해 이해하는 것이 중요하다.
여기서는 길이 N. 즉, 배열의 길이만이 중요한 State값이 된다. 아니 배열의 길이는 처음부터 정해진 것이 아닌가?
물론 전체 배열은 그렇지만, 우리가 작은 문제로 나누어서 생각한다면 배열의 길이가 1인 것부터 시작해서 그 최적값을 구해 전체 배열의 결과를 구할 수 있을 것이다. 따라서 길이 그 자체가 State가 된다.
State가 1차원이므로 작은 문제들의 결과값, 즉 DP의 결과를 저장할 배열을 lis[]라고 부르자. 그 크기는 기존 배열과 같게 생성하면 될 것이다.
그렇다면, 기저 상태는 어떻게 되나? 배열의 길이가 1일 때이다. 즉 N=1, index로는 0일 때, 그 자체로만 LIS가 되므로 그 상태 지정을 할 수 있다.
기저 상태 : lis[0] = 1
제일 중요한 점화식을 알아보자. LIS의 특성에 따라 점화식은 다음과 같이 지정할 수 있다.
점화식 : lis[i] = lis[j] + 1 (단, j < i and arr[j] < arr[i])
원 배열을 arr[]이라고 가정 시, 2가지의 조건을 충족해야 한다.
1) 현재 위치(i) 보다 이전 위치(j)와 비교한다.
2) 현재 위치(i)의 값(arr[i]) 보다 이전 위치(j)의 값(arr[j])가 더 작아야 한다.
위와 같을 때, LIS의 정의와 부합한다고 할 수 있을 것이다.
길이를 구했으면 실제 부분 수열 또한 구할 수 있어야 한다. 그 배열을 V[]라고 가정하고 아래의 배열을 예시로 보자.
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| seq[i] | 1 | 2 | 3 | 3 | 1 | 2 | 3 | 2 | 4 |
| V[i] | -1 | 0 | 1 | 1 | -1 | 4 | 5 | 4 | 6 |
위의 V배열을 이해해보자면, index 0의 위치한 arr[0]는 가장 처음에 무조건 와야 해서 이전에 더 작은 수가 없다. 따라서 -1로 초기화한다.
그 이후는 아래와 같다.
arr[1] 은 20. 이전의 작은 수 중 lis 길이가 가장 높은 수는 arr[0]. 따라서 V배열에 해당 index인 0을 저장.
arr[2] 는 40. 이전의 작은 수 중 lis 길이가 가장 높은 수는 arr[1]. 따라서 V배열에 해당 index인 1을 저장.
arr[3] 는 30. 이전의 작은 수 중 lis 길이가 가장 높은 수는 arr[1]. 따라서 V배열에 해당 index인 1을 저장.
arr[4] 는 1. 이전의 작은 수 중 lis 길이가 가장 높은 수는 없음. -1로 초기화.
arr[5] 는 3. 이전의 작은 수 중 lis 길이가 가장 높은 수는 arr[4]. 따라서 V배열에 해당 index인 4를 저장.
arr[6] 는 5. 이전의 작은 수 중 lis 길이가 가장 높은 수는 arr[5]. 따라서 V배열에 해당 index인 5를 저장.
arr[7] 는 2. 이전의 작은 수 중 lis 길이가 가장 높은 수는 arr[4]. 따라서 V배열에 해당 index인 4를 저장.
arr[8] 는 90. 이전의 작은 수 중 lis 길이가 가장 높은 수는 arr[6]. 따라서 V배열에 해당 index인 6를 저장.
-> 참고로 arr[2], arr[3]도 그렇지만 코드 상 가장 가까운 것으로 저장됨.
위의 내용이 이해가 된다면 모두 이해한 것이다. 즉, 바로 이전의 값들 중 현재 값보다 작지만 가장 lis 길이가 긴 것의 index 값을 지정하는 것이다.
이렇게 하면 왜 가능할까? 최후에 반환 시에, lis 길이가 가장 긴 V[8]=6을 반환하면, arr[V[8]] = arr[6] = 5 가 된다. 즉, 이렇게 거꾸로 돌아가면서 해당 index로 이동하며 전체 배열을 구할 수 있는 것이다!
아래와 같이 색상을 통해 더 쉽게 이해해보자.
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| seq[i] | 1 | 2 | 3 | 3 | 1 | 2 | 3 | 2 | 4 |
| V[i] | -1 | 0 | 1 | 1 | -1 | 4 | 5 | 4 | 6 |
뒤로 돌아가는 색상을 매칭 시켰다.
이에 따라 궁극적으로 구해지는 LIS 배열은 1, 3, 5, 90이 된다.
초기에 -1로 저장하는 이유는 더 이상 이전으로 갈 수 없음을 뜻하는 것으로 아래에서 printLIS에 조건을 보면 -1에 다다를 시 바로 출력 후 return을 하는 것을 알 수 있다.
코드를 통해 알아보자.
package com.test;
import java.io.*;
public class LIS{
static int[] arr; // 원 배열
static int[] lis; // LIS 길이 저장
static int[] V; // 이전 인덱스 저장
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
arr = new int[]{10, 20, 40, 30, 1, 3, 5, 2, 90};
lis = new int[arr.length];
V = new int[arr.length];
// 가장 긴 lis값을 갖는 index를 반환함
int result = dp();
bw.write("LIS 길이 : " + String.valueOf(lis[result]) + "\n");
// *********** 여기까지가 LIS 길이 구하는 부분. ***************
// LIS 길이 값 출력하기
bw.write("각 index의 LIS 값 : ");
for(int i=0; i < lis.length; i++){
bw.write(lis[i] + ", ");
}
bw.write("\n");
// LIS 배열 출력해보기
// 출력 시 뒤에서부터 lis 길이를 기준으로 써내려가야 한다.
// 앞에서부터 하면 제일 앞의 값이 가장 큰 값일 때, 그것을 걸러낼 수 없다.
bw.write("LIS 배열 출력하기" + "\n");
printLis(result, bw);
br.close();
bw.flush();
}
// Bottom-Up 방식으로 해결하는 DP
public static int dp(){
// 최대 lis 길이 값
int max_lis = 0;
// 최대 길이를 만족시키는 부분 수열의 마지막 인덱스, 초기는 0으로
int last = 0;
// lis[0]은 정해졌으니 그 이후부터 채워나감
for(int i=0; i < lis.length; i++){
lis[i] = 1; // 기본적으로 1로 초기화. 기저 상태도 초기화됨
V[i] = -1; // 기본적으로 -1로 초기화. 기저 상태로 초기화됨
// 자신보다 이전의 값들과 비교해야함. 그 중 가장 큰 값으로!
for(int j=i-1; j >= 0; j--){
// 이전 값이 더 작으면서 lis 길이 값은 같거나 큰 경우
if(arr[j] < arr[i] && lis[j] >= lis[i]){
lis[i] = lis[j] + 1;
V[i] = j; // 이전의 index 저장
}
if(max_lis < lis[i]){
max_lis = lis[i];
last = i; // 최대 길이가 변경되어야 한다.
}
}
}
return last;
}
// 재귀를 통해 LIS 배열 출력
private static void printLis(int idx, BufferedWriter bw) throws IOException{
// 더 갈 수 없는 가장 이전 index 까지 간 경우
if(V[idx] == -1) {
bw.write(arr[idx] + " ");
return;
}
printLis(V[idx], bw);
bw.write(arr[idx] + " ");
}
}
/*
결과
LIS 길이 : 4
각 index의 LIS 값
1, 2, 3, 3, 1, 2, 3, 2, 4,
LIS 배열 출력하기
1, 3, 5, 90,
*/
코드에서 보는 바와 같이 2중 반복문을 통해서 LIS를 구해나가고 있다. 따라서 이와 같은 풀이 방식은 시간복잡도가 O(N^2)이 된다. 완전 탐색의 경우보다는 낫지만.. 여전히 높은 시간복잡도가 요구되고 있다.
참고로 Top-Down으로 해결하는 방법은 아래와 같다. 필요 시 아래의 더보기를 클릭해서 코드를 알아보자.
package com.test;
import java.io.*;
public class LIS{
static int[] arr; // 원 배열
static int[] lis; // LIS 길이 저장
static int[] V; // 이전 인덱스 저장
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
arr = new int[]{10, 20, 40, 30, 1, 3, 5, 2, 90};
// 배열 정의 및 기저 상태 저장
lis = new int[arr.length]; lis[0] = 1;
V = new int[arr.length]; V[0] = -1;
int result = 0;
for(int i=0; i < lis.length; i++){
int temp = dp(i);
if(lis[result] < lis[temp]){
result = temp;
}
}
bw.write(String.valueOf("LIS의 길이 : " + lis[result]) + "\n");
// *********** 여기까지가 LIS 길이 구하는 부분. ***************
// LIS 길이 값 출력하기
bw.write("각 index의 LIS 값 : ");
for(int i=0; i < lis.length; i++){
bw.write(lis[i] + ", ");
}
bw.write("\n");
// LIS 배열 출력해보기
// 출력 시 뒤에서부터 lis 길이를 기준으로 써내려가야 한다.
// 앞에서부터 하면 제일 앞의 값이 가장 큰 값일 때, 그것을 걸러낼 수 없다.
bw.write("LIS 배열 출력하기" + "\n");
printLis(result, bw);
br.close();
bw.flush();
}
// Top-Down 방식으로 해결하는 DP
public static int dp(int n){
if(n == 0 || lis[n] > 0) return n; // 기저상태 또는 이미 이전의 값이 있는 경우 반환
lis[n] = 1; // 우선 1로 초기화
V[n] = -1; // 우선 -1로 초기화
// 자신보다 이전의 값들과 비교해야함. 그 중 가장 큰 값으로!
for(int i=n-1; i >= 0; i--){
// 우선 -1로 초기화
int temp = -1;
// 이전의 값이 더 작으면
if(arr[i] < arr[n]){
temp = dp(i);
}
// 만약 -1보다 크게 바뀌었고, lis 길이도 더 긴 경우
if(temp != -1 && lis[temp] >= lis[n]){
lis[n] = lis[temp] + 1;
V[n] = temp;
}
}
return n;
}
// 재귀를 통해 LIS 배열 출력
private static void printLis(int idx, BufferedWriter bw) throws IOException{
// 더 갈 수 없는 가장 이전 index 까지 간 경우
if(V[idx] == -1) {
bw.write(arr[idx] + " ");
return;
}
printLis(V[idx], bw);
bw.write(arr[idx] + " ");
}
}
/*
결과
LIS 길이 : 4
각 index의 LIS 값
1, 2, 3, 3, 1, 2, 3, 2, 4,
LIS 배열 출력하기
10, 20, 40, 90,
*/
③ Nlogn으로 개선하기
완전 탐색에서 DP까지 사용하며 LIS를 해결할 수 있는 방법을 알아보았지만 시간복잡도가 여전히 높은 수준이다. 더 개선할 수 있는 방법을 알아보자.
여기서의 아이디어는 다음과 같다.
1) 추가 배열을 만들고 원 배열을 탐색하며 큰 수는 추가 배열에 이어 붙인다.
2) 추가 배열의 마지막에 추가된 값보다 작은 값은 이분 탐색을 통해 적절한 자리를 찾아 교환한다.
이 방법의 장점은 이분 탐색을 통해 빠르게 LIS의 길이를 구할 수 있다는 것이다.
이 방법의 단점은 LIS 배열 그 자체는 중간에 값이 교체되기 때문에 구할 수 없을 수도 있다는 것이다.
이해를 돕기 위해 다음과 같이 그림으로 알아보자.
원 배열은 다음과 같다. 추가 배열은 lis[] 라고 생각해보자
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] |
1) 인덱스 0 탐색(arr[0])
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] | 10 |
arr[0]은 최초의 값이므로 그냥 바로 lis 배열에 추가한다.
현재 마지막 추가된 값 : 10
2) 인덱스 1 탐색(arr[1])
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] | 10 | 20 |
이전 lis 배열의 마지막 값은 10이었다. arr[1]=20으로 이전 수보다 크기 때문에 바로 lis 배열에 추가할 수 있다.
현재 마지막 추가된 값 : 20
3) 인덱스 2 탐색(arr[2])
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] | 10 | 20 | 40 |
이전 lis 배열의 마지막 값은 20이었다. arr[2]=40으로 이전 수보다 크기 때문에 바로 lis 배열에 추가할 수 있다.
현재 마지막 추가된 값 : 40
4) 인덱스 3 탐색(arr[3])
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] | 10 | 20 | 30 |
이전 lis 배열의 마지막 값은 40이었다. arr[3]=30으로 이전 수보다 작은데, 순서 상 교체될 수 있는 위치는 lis[2]이므로 교체한다.
현재 마지막 추가된 값 : 30
5) 인덱스 4 탐색(arr[4])
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] | 1 | 20 | 30 |
이전 lis 배열의 마지막 값은 30이었다. arr[4]=1으로 이전 수보다 작은데, 순서 상 교체될 수 있는 위치는 lis[0]이므로 교체한다.
현재 마지막 추가된 값 : 30
6) 인덱스 5 탐색(arr[5])
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] | 1 | 3 | 30 |
이전 lis 배열의 마지막 값은 30이었다. arr[5]=3으로 이전 수보다 작은데, 순서 상 교체될 수 있는 위치는 lis[1]이므로 교체한다.
현재 마지막 추가된 값 : 30
7) 인덱스 6 탐색(arr[6])
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] | 1 | 3 | 5 |
이전 lis 배열의 마지막 값은 30이었다. arr[6]=5으로 이전 수보다 작은데, 순서 상 교체될 수 있는 위치는 lis[2]이므로 교체한다.
현재 마지막 추가된 값 : 5
8) 인덱스 7 탐색(arr[7])
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] | 1 | 2 | 5 |
이전 lis 배열의 마지막 값은 5이었다. arr[7]=2로 이전 수보다 작은데, 순서 상 교체될 수 있는 위치는 lis[1]이므로 교체한다.
현재 마지막 추가된 값 : 5
9) 인덱스 8 탐색(arr[8])
| 인덱스 i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| arr[i] | 10 | 20 | 40 | 30 | 1 | 3 | 5 | 2 | 90 |
| lis[i] | 1 | 2 | 5 | 90 |
이전 lis 배열의 마지막 값은 5이었다. arr[8]=90로 이전 수보다 크니, 마지막에 추가한다.
현재 마지막 추가된 값 : 90
위와 같이 구한 결과 전체 LIS의 길이는 4라는 것을 알 수 있다. 하지만 상단에 단점에 대해 설명했듯이, 중간에 교체되어 lis배열이 실제 lis라고 볼 수는 없게 된다.
실제로도 arr배열에서 1, 2, 5, 90이라는 LIS는 없다.
이것을 코드로 푸는 방법은 다음과 같다.
package com.test;
import java.util.*;
public class LIS{
static int[] arr;
static int[] lis;
public static void main(String[] args){
arr = new int[]{10, 20, 40, 30, 1, 3, 5, 2, 90};
lis = new int[arr.length];
Arrays.fill(list, Integer.MAX_VALUE);
lis[0] = arr[0]; // 최초의 index 0의 값은 arr[0]이 된다.
int idx = 0;
for(int i=1; i < arr.length; i++){
// 만약 원 배열이 탐색 중 더 큰 숫자라면 그대로 이어서 붙인다.
if(lis[idx] < arr[i]){
lis[++idx] = arr[i];
// 그렇지 않고 작다면 이진 탐색(Binary Search)를 통해 교체를 수행한다.
} else {
int target_index = binarySearch(lis, arr[i]);
lis[target_index] = arr[i];
}
}
// 현재 idx의 값에서 1을 더한 것이 바로 전체 LIS의 길이가 된다.
System.out.println("LIS 길이 : " + (idx+1));
}
// 반복문을 이용한 이진 탐색 방식
public static int binarySearch(int[] arr, int x){
int start = 0;
int end = arr.length-1;
// 현재 탐색한 위치가 찾고자 하는 값보다 크냐 작냐에 따라 중간 index 계산을 위한 start / end 값을 변경함
while(start < end){
int mid = (start + end) / 2;
if(arr[mid] == x){
return mid;
} else if(arr[mid] < x){
start = mid + 1;
} else {
end = mid-1;
}
}
// 일치값을 찾지 못했을 때, -1이 아니라 그 적절한 위치를 반환해야 함
return start;
}
}
/*
결과
LIS 길이 : 4
각 index의 LIS 값
1, 2, 3, 3, 1, 2, 3, 2, 4,
LIS 배열 출력하기
10, 20, 40, 90,
*/
배열을 탐색하며 이진 탐색을 통해 진행하므로 배열 탐색에 O(n), 이진 탐색에 O(logn)이 소요되어 총 시간복잡도는 O(nlogn)이 된다.
긴 글 읽어주셔서 감사합니다. 오류가 있다면 지적해주시면 수정하겠습니다.
'자바 프로그래밍 > 알고리즘(Algorithm)' 카테고리의 다른 글
| 알고리즘 - 백트래킹(Backtracking) (2) | 2021.02.03 |
|---|---|
| 알고리즘 - 완전탐색(Exhaustive Search) (6) | 2021.01.19 |
| 알고리즘 - Dynamic Programming(동적 계획법) (36) | 2021.01.05 |
| 알고리즘 - 진법 변환하기(10진수 - N진수) (2) | 2020.12.29 |
| 알고리즘 - 그래프 탐색(깊이 우선 탐색 - DFS) (0) | 2020.12.08 |

