전체 정렬 개요의 설명은 여기를 참조
Bubble / Selection / Insertion 정렬의 설명은 여기를 참조
Merge 정렬의 설명은 여기를 참조
Quick 정렬의 설명은 여기를 참조
Heap 정렬은 우선순위 큐에서 사용하는 정렬이므로 해당 포스팅 여기를 참조
Counting 정렬의 설명은 여기를 참조
Radix 정렬의 설명은 여기를 참조
Bucket 정렬의 설명은 여기를 참조
Topological 정렬의 설명은 여기를 참조
Shell Sort(셸 정렬)
애니메이션을 보아도 이해가 어렵겠지만 참고적으로 살펴보자.
셸 정렬은 'Donald L. Shell' 이 제안한 방법으로, 지난 포스팅의 삽입 정렬(Insertion Sort)를 보완한 방식이다. 삽입 정렬의 문제점은 무엇이 있을까?
삽입 정렬은 이전의 포스팅을 보면 알 수 있지만, 각 데이터가 삽입될 적절한 위치를 찾기 위해서 인접한 데이터와의 여러 번의 비교 과정을 거쳐야만 한다. 그런데, 이 삽입 정렬은 Nearly Sorted 상태의 데이터라면 O(n)에 가까운 매우 빠른 성능을 보여준다는 장점이 있다.
그래서 셸 정렬은 기존의 삽입 정렬을 수행하기 전에 전체 데이터를 Nearly Sorted 형태로 만들면 기존의 삽입 정렬을 그대로 처음부터 적용하는 것보다 더 좋은 성능을 발휘할 수 있다는 점에 착안한 것이다.
우선 셸 정렬의 특징은 다음과 같다.
| 특성 | 설명 |
| In-place 알고리즘 | Memory 상에서 필요 시 상호 위치만 변경될 뿐 추가적인 배열 생성이 불 필요함 |
| Unstable 알고리즘 | 같은 값의 데이터의 기존 순서 유지를 보장할 수 없다. |
삽입 정렬의 시간 / 공간 복잡도는 아래와 같다.
| 알고리즘 | 시간복잡도(최상) | 시간복잡도(평균) | 시간복잡도(최악) | 공간복잡도 |
| 셸 정렬 | O(n) | O(nlogn) | O(n^2) | O(1) |
셸 정렬의 동작 방식은 삽입 정렬과 동일하다. 그런데, 기존 삽입 정렬은 삽입 위치를 찾기 위해 인접 값들끼리만 비교했다면 셸 정렬은 Gap 을 두어 인접하지 않은 값들 끼리 비교한다.
그리고 그 Gap을 줄여가는데, Gap이 1이 되면 삽입 정렬과 동일한 상태로 동작하게 된다. Gap이 1이 되기 전까지 전체 데이터는 Nearly Sorted 상태가 되는 것이다.
셸 정렬이 Unstable한 이유는 이 Gap을 통해 인접하지 않은 값 끼리의 교환이 일어날 수 있기 때문이다. 이제 어떻게 셸 정렬이 동작하는지 알아보자.
초기 상태의 배열이 아래와 같다고 하자.

여기서, 정렬은 0번 부터 시작하지만 0번의 데이터와 비교할 값은 0+k번째 데이터이다. 여기서 k는 Gap을 의미한다. 이 k를 초기에 (전체 정렬할 데이터의 수 / 2)로 정해서 시작한다고 하자.
① k = (10 / 2) = 5 일 때, 비교 및 정렬 후 상태
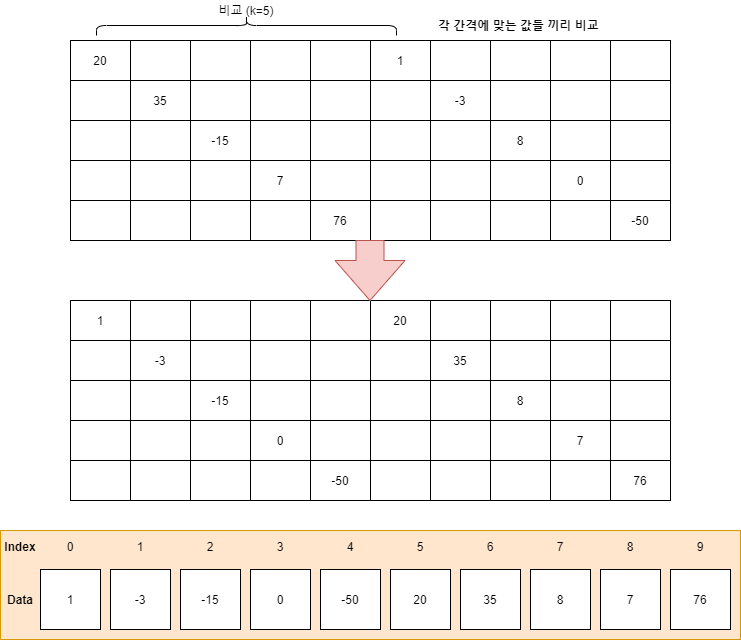
1차적으로 정렬을 완료하였으니 Gap을 줄일 차례다. Gap은 여기서 기존의 값에서 절반으로 줄인다. 되도록 홀수가 나오도록 하는 것이 좋다. 그러니 5 / 2 = 2.5 이므로 반올림하여 3으로 만들자. 현재의 Gap = 3 이다.
② k = 3 일 때, 비교 및 정렬 후 상태

마지막으로 Gap이 1이 되어 삽입 정렬을 시도하면 전체적으로 Nearly Sorted 상태가 되어 매우 빠른 성능으로 전체 데이터 정렬이 완료된다.
③ 마지막 Gap=1일 때, 삽입 정렬을 시도한 결과

여기까지 셸 정렬의 방법을 모두 알아보았다. 이제 코드로 구현하는 방법을 알아보자. 아래와 같다.
package com.test;
public class ShellSort {
public static void main(String[] args){
int[] intArray = {20, 35, -15, 7, 55, 1, -22};
// Gap에 따라 정렬 하기 위해 Gap을 이용한 반복문을 생성함
for(int gap = intArray.length / 2; gap > 0; gap /= 2){
// Gap의 크기에 맞게 최초 정렬을 시작할 기준을 지정하여 반복문 형성
for(int i=gap; i < intArray.length; i++) {
// i에 지정된 값에 해당하는 Value를 정렬 시를 대비해 미리 저장해 둠
int newElement = intArray[i];
// j를 이용해 Gap 만큼의 반복 정렬을 수행할 것이므로 따로 저장
int j = i;
// 해당 반복 정렬을 조건이 참인 경우 수행
// 해당 조건은, j의 index 값이 gap보다 커야 하며, j-gap의 index에 지정 된 배열 값이 이전에 저장된 내용보다 큰 경우
while (j >= gap & intArray[j - gap] > newElement) {
// 해당 값을 뒤 쪽으로 미루어 저장
intArray[j] = intArray[j - gap];
// 반복 비교를 위해 gap만큼 차감
j -= gap;
}
// 기존에 저장한 배열 값을 저장
intArray[j] = newElement;
}
}
for(int i=0; i < intArray.length; i++){
if(i == intArray.length-1){
System.out.print(intArray[i]);
} else {
System.out.print(intArray[i] + ", ");
}
}
}
}
마지막으로, Gap을 어떻게 결정하여 정렬하는 것이 좋은지에 대해 포스팅하고 마무리 한다.
위의 예시에서는 사실 Gap Sequence를 단순히 전체 배열의 크기에서 시작해 2로 나누어가며 진행했지만, 실제로는 연구에 의해 또는 실험적으로 Best Gap Sequence 라는 것이 제공되고 있다.
위키피디아를 참고한다면 여러 가지 방법론이 있는 것을 확인할 수 있지만, 대표적으로 Knuth Sequence와 Ciura Sequence에 대해 간단히 언급하고 마무리 하자.
Knuth Sequence는 Gap이 다음과 같은 순서로 결정된다.
1, 4, 13, 40, 121 ...
수식은 어렵지 않다. (3^K - 1 / 2) 로 결정되며 전체 배열의 크기가 N이라면 Gap은 N/3 보다 작은 수 중 가장 큰 값으로 결정 된다.
즉, 만약 배열의 크기가 100이라면, 33.333이므로 Gap은 13부터 시작해 4, 1로 내려가면서 마무리한다.
Ciura Sequence는 Gap이 다음과 같은 순서로 결정된다.
1, 4, 10, 23, 57, 132, 301, 701 ...
별도의 수식이 정해져 있지 않고, 실험적으로 결정된 값이다. 701 이후의 값은 딱히 나와있지 않다. 현재 배열의 크기보다 작은 수 중 가장 큰 값부터 시작하여 1까지 내려가면 된다.
오류가 있는 부분은 댓글로 남겨주시면 반영하겠습니다. 감사합니다.
'자바 프로그래밍 > 자료구조(Data Structure)' 카테고리의 다른 글
| 자료구조 - 정렬 4 (Quick) (0) | 2020.11.13 |
|---|---|
| 자료구조 - 정렬 3 (Merge) (0) | 2020.11.09 |
| 자료구조 - 정렬 1 (Bubble / Selection / Insertion) (0) | 2020.11.07 |
| 자료구조 - 정렬 (개요) (0) | 2020.11.06 |
| 자료구조 - 세그먼트 트리(Segment Tree)2 - 느린 전파 (0) | 2020.11.02 |

